Developing a real Rails application
This chapter gets you started on building a Ruby on Rails application from scratch using the techniques covered in the previous chapter, plus a couple of new ones. With the techniques you learned in chapter 2, you can write features describing the behavior of the specific actions in your application and then implement the code you need to get the feature passing.
The great thing about having these tests written is that whenever you want to verify that the application is behaving as you wanted, you can run these automated tests very quickly to find out.
In the rest of this book, we’re going to be building a new application from the ground up. We’ll do this by focussing on one feature at a time, writing tests for that feature and then implementing behaviour to make those tests pass.
For this example application, your imaginary client, who has limitless time and budget (unlike clients in the real world), wants you to develop a ticket-tracking application to track the company’s numerous projects.
You’ll work iteratively, delivering small working pieces of the software to the client and then gathering the client’s feedback to improve the application as necessary. If no improvement is needed, you can move on to the next prioritized chunk of work.
The first couple of features you develop for this application will lay down the foundation for the application, enabling people to create projects and tickets. Later, in chapters 7 and 8, you’ll implement authentication and authorization so that people can sign in to the application. Other chapters cover things like adding comments to tickets, notifying users by email and file uploading in chapter 9.
All the way through this application’s development process we will be writing tests. This provides the client with a stable application; and when (not if) a bug crops up, you have a nice test base you can use to determine what’s broken. Then you can fix the bug so it doesn’t happen again, a process called regression testing.
Overall, this development process is called behavior-driven development. We will start by writing tests that describe the behavior that we want the application to have, and then we will set about writing code to make those tests pass.
As you work with your client to build the features of the application using this behavior-driven development technique, the client may ask why all this prework is necessary. This can be a tricky question to answer. Explain that writing the tests before the code and then implementing the code to make the tests pass creates a safety net to ensure that the code is always working. (Note that tests will make your code more maintainable, but they won’t make your code bug-proof.)
The tests also give you a clearer picture of what your client really wants. Having it all written down in code gives you a solid reference to point to if clients say they suggested something different.
By using behaviour-driven development, you know what clients want, clients know you know what they want, you have something you can run automated tests with to ensure that all the pieces are working, and, finally, if something does break, you have the test suite in place to catch it. It’s a win-win-win situation.
Some of the concepts covered in this chapter were explained in chapter 1. But
rather than using scaffolding, as you did previously, you’ll write this
application from the ground up using the BDD process and other generators
provided by Rails. The scaffold generator is great for prototyping, but it’s
less than ideal for delivering simple, well-tested code that works precisely
the way you want it to work. The code provided by the scaffold generator often
may differ from the code you want. In this case, you can turn to Rails for
lightweight alternatives to the scaffold code options, and you’ll likely end
up with cleaner, better code.
First, you need to set up your application!
First steps
Chapter 1 explained how to quickly start a Rails application. This chapter explains a couple of additional processes that improve the flow of your application development. One process uses BDD to create the features of the application; the other process uses version control. Both will make your life easier.
The application story
Your client may have a good idea of the application they want you to develop. How can you transform the idea in your client’s brain into beautifully formed code? First, you sit down with your client and talk through the parts of the application. In the programming business, we call these parts user stories, and you’ll use RSpec and Capybara to develop them.
Start with the most basic story, and ask your client how they want it to behave. Then sketch out a basic flow of how the feature would work by building an acceptance test using RSpec and Capybara. If this feature was a login form, the test for it would look something like this:
RSpec.feature "Users can log in to the site" do
scenario "as a user with a valid account" do
visit "/login"
fill_in "Email", with: "user@ticketee.com"
fill_in "Password", with: "password"
click_button "Login"
expect(page).to have_content("You have been successfully logged in.")
end
endThe form of this test is simple enough that even people who don’t understand Ruby should be able to understand the flow of it. With the function and form laid out, you have a pretty good idea of what the client wants.
Laying the foundations
To start building the application you’ll be developing throughout this book,
run the good-old rails command, preferably outside the directory of the
previous application. Call this app ticketee, the Australian slang for a
person who validates tickets on trains in an attempt to catch fare evaders. It
also has to do with this project being a ticket-tracking application, and a
Rails application, at that.[1] To generate this application, run this command:
$ rails new ticketee
|
Help!
If you want to see what else you can do with this $ rails new --help The |
Presto, it’s done! From this bare-bones application, you’ll build an application that does the following:
-
Tracks tickets (of course) and groups them into projects
-
Provides a way to restrict users to certain projects
-
Allows users to upload files to tickets
-
Lets users tag tickets so they’re easy to find
You can’t do all this with a command as simple as rails new [application_name],
but you can do it step by step and test it along the
way so you develop a stable and worthwhile application.
Throughout the development of the application, we advise you to use a version-control system. The next section covers that topic using Git. You’re welcome to use a different version-control system, but this book uses Git exclusively.
Version control
It is wise during development to use version-control software to provide checkpoints in your code. When the code is working, you can make a commit; and if anything goes wrong later in development, you can revert back to that known-working commit. Additionally, you can create branches for experimental features and work on those independent of the main codebase, without damaging working code.
This book doesn’t go into detail on how to use a version-control system, but it does recommend using Git. Git is a distributed version-control system that is easy to use and extremely powerful. If you wish to learn about Git, we recommend reading Pro Git, a free online book by Scott Chacon (Apress, 2014, http://git-scm.com/book/en/v2).
Git is used by most developers in the Rails community and by tools such as Bundler, discussed shortly. Learning Git along with Rails is advantageous when you come across a gem or plug-in that you have to install using Git. Because most of the Rails community uses Git, you can find a lot of information about how to use it with Rails (even in this book!) should you ever get stuck.
If you don’t have Git already installed, GitHub’s help site offers installation guides for these platforms:
The precompiled installer should work well for Macs, and the
package-distributed versions (via apt, yum, emerge, and so on) work well for Linux machines. For
Windows, the GitHub for Windows program does just fine.
Getting started with GitHub
For an online place to put your Git repository, we recommend GitHub
(http://github.com), which offers free accounts.[2] If you set up an account now,
you can upload your code to GitHub as you progress, ensuring that you won’t
lose it if anything were to happen to your computer. To get started with
GitHub, you first need to generate a secure shell (SSH) key, which is used to
authenticate you with GitHub when you do a git push to GitHub’s servers. You can find a guide for this process at https://help.github.com/articles/generating-ssh-keys.
When you’ve setup your account, it is now time to create a new repository called "ticketee" on your GitHub account. You can follow the steps in this guide to do that: https://docs.github.com/en/get-started/quickstart/create-a-repo.
Now you’re on your project’s page. It has some basic instructions on how to set up your code in your new repository, but first you need to configure Git on your own machine. Git needs to know a bit about you for identification purposes - so you can properly be credited (or blamed) for any code that you write.
Configuring your Git client
Run the commands below in your terminal or command prompt to tell Git
about yourself, replacing "Your Name" with your real name and you@example.com
with your email address. The email address you provide should be the
same as the one you used to sign up to GitHub, so that when you push your code
to GitHub, it will also be linked to your account.
$ git config --global user.name "Your Name" $ git config --global user.email you@example.com
Next, we’ll need to go into the new application’s directory:
cd ticketee
Then we will add all the files for your application to this repository’s staging area, by running:
$ git add .
The staging area for the repository is the location where all the changes for the next commit are kept. A commit can be considered a checkpoint for your code. If you make a change, you must stage that change before you can create a commit for it. To create a commit with a message, run
$ git commit -m "Generate the Rails 7 application"
This command generates quite a bit of output, but the most important lines are the first two:
[develop (root-commit) fd1b36f] Generate the Rails 7 application 78 files changed, 1377 insertions(+)
fd1b36f is the short commit ID, a unique identifier for the commit, so it
changes with each commit you make. The number of files and insertions may also
be different. In Git, commits are tracked against branches, and the default
branch for a Git repository is the develop branch, which you just committed to.
The second line lists the number of files changed, insertions (new lines added) and deletions. If you modify a line, it’s counted as both an insertion and a deletion, because, according to Git, you’ve removed the line and replaced it with the modified version.
To view a list of commits for the current branch, type git log. You should
see output similar to the following listing.
commit fd1b36ff35324ee6f581cf11699c648fd1bf6318 (HEAD -> develop)
Author: Your Name <you@example.com>
Date: [date stamp]
Generate the Rails 7 application
The hash after the word commit is the long commit ID; it’s the longer
version of the previously sighted short commit ID. A commit can be
referenced by either the long or the short commit ID in Git, providing no
two commits begin with the same short ID.[3] With that commit in your repository,
you have something to push to GitHub, which you can do by running the following,
making sure to substitute your own GitHub username in:
$ git remote add origin git@github.com:[your username]/ticketee.git $ git push origin develop -u
The first command tells Git that you have a remote server called origin for
this repository. To access it, you use the git@github.com:[your username]/ticketee.git
path, which connects to the repository you created on GitHub, using SSH. The next command pushes the named branch to
that remote server, and the -u option tells Git to always pull
from this remote server for this branch unless told differently. The output from this command
is similar to the following.
git push outputCounting objects: 73, done. Compressing objects: 100% (58/58), done. Writing objects: 100% (73/73), 86.50 KiB, done. Total 73 (delta 2), reused 0 (delta 0) To git@github.com:rubysherpas/active_rails_examples.git * [new branch] develop -> develop Branch develop set up to track remote branch develop from origin.
The second-to-last line in this output indicates that your push to GitHub
succeeded, because it shows that a new branch called develop was created on GitHub. Note that
as we go through the book, we’ll also git push just like
you. You can compare your code to ours by checking out our repository on GitHub:
https://github.com/rubysherpas/active_rails_examples.
To roll back the code to a given point in time, check out git log. What you’ll see will be different to what we show below, but it will look similar:
commit d1e9b6f398748d3ca8583727c1f86496465ba298
Author: [name] <[email redacted]>
Date: [timestamp]
Protect state_id from users who do not have permission
to change it
commit ceb67d45cfcddbb8439da7b126802e6a48b1b9ea
Author: [name] <[email redacted]>
Date: [timestamp]
Only admins and managers can change states of a ticket
commit ef5ec0f15e7add662852d6634de50648373f6116
Author: [name] <[email redacted]>
Date: [timestamp]
Auto-assign the default state to newly-created tickets
Each of these lines represents a commit, and the commits line up with when we tell you to commit in the book. You can also check out the commit list on GitHub, if you find that easier: https://github.com/rubysherpas/active_rails_examples/commits.
Once you’ve found the commit you want to go back to, make note of the long commit
ID associated with it. Use
this value with git checkout to roll the code back in time:
$ git checkout 23729a
You only need to know enough of the hash for it to be unique: six
characters is usually enough. When you’re done poking around, go forward in time to the most
recent commit with git checkout again:
$ git checkout develop
This is a tiny, tiny taste of the power of Git. Time travel at will! You just have to learn the commands.
Next, you must set up your application to use RSpec.
Application configuration
Even though Rails passionately promotes the convention over configuration line, some parts of the application still will need configuration. It’s impossible to avoid all configuration. The main parts are gem dependency configuration, database settings, and styling. Let’s look at these parts now.
The Gemfile and generators
The Gemfile is used for tracking which gems are used in your application. "Gem"
is the Ruby word for a library of code, all packaged up to be included into your
app - Rails is a gem, and it in turn depends on many other gems. Bundler is a gem, and
Bundler is also responsible for everything to do with this Gemfile. It’s
Bundler’s job to ensure that all the gems listed inside the Gemfile are installed
when your application is initialized. Let’s look at the following listing to see
how it looks inside.
source "https://rubygems.org"
git_source(:github) { |repo| "https://github.com/#{repo}.git" }
ruby "3.1.2"
# Bundle edge Rails instead: gem "rails", github: "rails/rails", branch: "main"
gem "rails", "~> 7.0.3"
# The original asset pipeline for Rails [https://github.com/rails/sprockets-rails]
gem "sprockets-rails"
# Use sqlite3 as the database for Active Record
gem "sqlite3", "~> 1.4"
# Use the Puma web server [https://github.com/puma/puma]
gem "puma", "~> 5.0"
# Use JavaScript with ESM import maps [https://github.com/rails/importmap-rails]
gem "importmap-rails"
# Hotwire's SPA-like page accelerator [https://turbo.hotwired.dev]
gem "turbo-rails"
# Hotwire's modest JavaScript framework [https://stimulus.hotwired.dev]
gem "stimulus-rails"
# Build JSON APIs with ease [https://github.com/rails/jbuilder]
gem "jbuilder"
# Use Redis adapter to run Action Cable in production
gem "redis", "~> 4.0"
# Use Kredis to get higher-level data types in Redis [https://github.com/rails/kredis]
# gem "kredis"
# Use Active Model has_secure_password [https://guides.rubyonrails.org/active_model_basics.html#securepassword]
# gem "bcrypt", "~> 3.1.7"
# Windows does not include zoneinfo files, so bundle the tzinfo-data gem
gem "tzinfo-data", platforms: %i[ mingw mswin x64_mingw jruby ]
# Reduces boot times through caching; required in config/boot.rb
gem "bootsnap", require: false
# Use Sass to process CSS
# gem "sassc-rails"
# Use Active Storage variants [https://guides.rubyonrails.org/active_storage_overview.html#transforming-images]
# gem "image_processing", "~> 1.2"
group :development, :test do
# See https://guides.rubyonrails.org/debugging_rails_applications.html#debugging-with-the-debug-gem
gem "debug", platforms: %i[ mri mingw x64_mingw ]
end
group :development do
# Use console on exceptions pages [https://github.com/rails/web-console]
gem "web-console"
# Add speed badges [https://github.com/MiniProfiler/rack-mini-profiler]
# gem "rack-mini-profiler"
# Speed up commands on slow machines / big apps [https://github.com/rails/spring]
# gem "spring"
end
group :test do
# Use system testing [https://guides.rubyonrails.org/testing.html#system-testing]
gem "capybara"
gem "selenium-webdriver"
gem "webdrivers"
endIn this file, Rails sets a source to be https://rubygems.org (the canonical
repository for Ruby gems). All gems you specify for your application are
gathered from the source. Next, it tells Bundler it requires version 6.1.0 of
the rails gem. Bundler inspects the dependencies of the requested gem, as well
as all gem dependencies of those dependencies (and so on), and then does what
it needs to do to make them all available to your application.
This file also requires the sqlite3 gem, which is used for interacting with
SQLite3 databases, the default when working with Rails. If you were to use
another database system, you would need to take out this line and replace it
with the relevant gem, such as mysql2 for MySQL or pg for PostgreSQL.
Groups in the Gemfile are used to define gems that should be loaded in
specific scenarios. When using Bundler with Rails, you can specify a gem group
for each Rails environment, and by doing so, you specify which gems should
be required by that environment. A default Rails application has three
standard environments: development, test, and production.
Rails application environments
The development environment is used for your local application, such as when you’re playing with it in the browser on your local machine. In development mode, page and class caching are turned off, so requests may take a little longer than they do in production mode. (Don’t worry—this is only the case for larger applications.) Things like more detailed error messages are also turned on, for easier debugging.
The test environment is used when you run the automated test suite for the application. This environment is kept separate from the development environment so your tests start with a clean database to ensure predictability, and so you can include extra gems specifically to aid in testing.
The production environment is used when you finally deploy your application out into the world for others to use. This mode is designed for speed, and any changes you make to your application’s classes aren’t effective until the server is restarted.
This automatic requiring of gems in the Rails environment groups is done
by this line in config/application.rb:
Bundler.require(*Rails.groups)The Rails.groups line provides two groups for Bundler to require: default
and development. The latter will change depending on the environment that
you’re running. This code will tell Bundler to load only the gems in the
"default" group (which is all gems not in any specific group), as well as any
gems in a group that has the same name as the environment.
Starting with Behavior Driven Development
Chapter 2 focused on Behavior Driven Development (BDD), and, as was more than hinted at, you’ll be using it
to develop this application. To get started, alter the Gemfile to ensure that you have
the correct gem for RSpec for your application. To add the rspec-rails gem, we’ll
add this line to the :development, :test group in our Gemfile:
group :development, :test do
# See https://guides.rubyonrails.org/debugging_rails_applications.html#debugging-with-the-debug-gem
gem "debug", platforms: %i[ mri mingw x64_mingw ]
gem 'rspec-rails', '~> 5.1'
endThis group in our Gemfile lists all the gems that will be loaded in the development
and test environments of our application. These gems will not be available in a
production environment. We’re adding rspec-rails to this group because we’re
going to need a generator from it to be available in development. Additionally, when
you run a generator for a controller or model, it’ll use RSpec, rather than the default
Test::Unit, to generate the tests for that class.
You’ve specified a version number with ~> 4.0.0 [4] which tells RubyGems you want
rspec-rails version 4.0.0 or higher, but less than rspec-rails
4.1.0. This means when RSpec releases 4.0.1 and you go to install your gems,
RubyGems will install the latest version it can find, rather than only 4.0.1.
The other gem that we’ll be using here is the capybara gem, but that is already in our Gemfile:
group :test do
# Adds support for Capybara system testing and selenium driver
gem 'capybara'
gem 'selenium-webdriver'
# Easy installation and use of web drivers to run system tests with browsers
gem 'webdrivers'
endAs we saw in the last chapter, Capybara can simulate actions on our application, allowing us to test the application automatically.
Capybara also supports real browser testing. If you tell RSpec that your test is a JavaScript test, it will open a new Firefox window and run the test there - you’ll actually be able to see your tests as they occur, and your application will behave exactly the same as it does when you view it yourself. You’ll use this extensively when we start writing JavaScript in chapter 9.
To install these gems to your system, run this command:
bundle install
With the necessary gems for the application installed, you should next run the
rspec:install generator, a generator provided by RSpec to set your Rails
application up for testing.
$ rails g rspec:install
|
Remember, |
You can also remove the default generated test directory in the root folder of your
application - you won’t be using it. You’ll write tests under the spec directory instead.
With this generated code in place, you should make a commit so you have another base to roll back to if anything goes wrong:
$ git add . $ git commit -m "Set up gem dependencies and run RSpec generator" $ git push
Beginning your first feature
You now have version control for your application, and you’re safely storing the code for it on GitHub. It’s now time to write your first Capybara-based test, which isn’t nearly as daunting as it sounds. We’ll explore things such as models and RESTful routing while you do it. It’ll be simple, promise!
Creating projects
The CRUD (create, read, update, delete) acronym is something you will see all the time in the Rails world. It represents the creation, reading, updating, and deleting of something, but it doesn’t say what that something is.
In the Rails world, CRUD is usually referred to when talking about resources. Resources are the representation of the information throughout your application - the "things" that your application is designed to manage. The following section goes through the beginnings of generating a CRUD interface for a project resource, by applying the BDD practices you learned in chapter 2 to the application you just bootstrapped. What comes next is a sampler of how to apply these practices when developing a Rails application. Throughout the remainder of the book, you’ll continue to apply these practices to ensure that you have a stable and maintainable application. Let’s get into it!
The first story for your application is the creation (the C in CRUD). You’ll create a resource representing projects in your application by first writing a test for the process by which a user will create projects, then creating a controller and model, and then creating a route. Then you’ll add a validation to ensure that no project can be created without a name. When you’re done with this feature, you’ll have a form that looks like this:
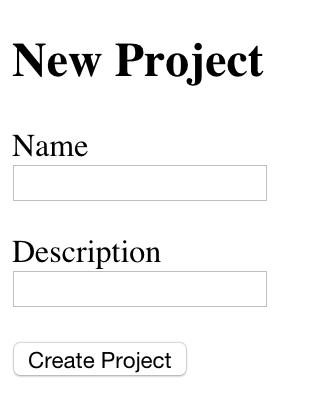
First, create a new directory at spec/features - all of the specs covering our
features will go there. Then, in a file called
spec/features/creating_projects_spec.rb, you’ll put the test that will make
sure this feature works correctly when it’s fully implemented. This code is
shown in the following listing.
require "rails_helper"
RSpec.feature "Users can create new projects" do
scenario "with valid attributes" do
visit "/"
click_link "New Project"
fill_in "Name", with: "Visual Studio Code"
fill_in "Description", with: "Code Editing. Redefined"
click_button "Create Project"
expect(page).to have_content "Project has been created."
end
endTo run this test, run this command from inside the ticketee directory:
bundle exec rspec
This command will run all of your specs and display your application’s first test’s first failure:
1) Users can create new projects with valid attributes
Failure/Error: visit "/"
ActionController::RoutingError:
No route matches [GET] "/"
It falls on the application’s router to figure out where the request should go. Typically, the request would be routed to an action in a controller, but at the moment there’s no routes at all for the application. With no routes, the Rails router can’t find the route for "/" and so gives you the error shown.
You have to tell Rails what to do with a request for /. You can do this
easily in config/routes.rb. At the moment, this file has the following content:
Rails.application.routes.draw do
# Define your application routes per the DSL in https://guides.rubyonrails.org/routing.html
# Defines the root path route ("/")
# root "articles#index"
endTo define a root route, you use the
root method like this in the block for the draw method:
Rails.application.routes.draw do
root "projects#index"
endThis defines a route for requests to / (the root route) to point at the
index action of the ProjectsController. This means that when anyone visits the "root" path of our application (for example: http://localhost:3000), they will see this page.
This controller doesn’t exist yet, and so the test should probably complain about that if you got the route right. Run bundle exec rspec to find out:
1) Users can create new projects with valid attributes
Failure/Error: visit "/"
ActionController::RoutingError:
uninitialized constant ProjectsController
This error is happening because the route is pointing at a controller
that doesn’t exist. When the request is made, the router attempts to load the controller,
and because it can’t find it, you’ll get this error. To define this ProjectsController
constant, you must generate a controller. The controller is the first port
of call for your routes (as you can see now!) and is responsible for querying the model for
information in an action and then doing something with that information (such as rendering a
template). (Lots of new terms are explained later. Patience, grasshopper.) To generate this
controller, run this command:
$ rails g controller projects
You may be wondering why we’re using a pluralized name for the controller. Well, the controller is going to be dealing with a plural number of projects during its lifetime, and so it only makes sense to name it like this. The models are singular because their name refers to their type. Another way to put it: you’re a Human, not a Humans. But a controller that dealt with multiple humans would be called HumansController.
The controller generator produces output similar to the output produced when
you ran rails new earlier, but this time it creates files just for the
controller we’ve asked Rails to generate. The most important of these is the controller itself,
which is housed in app/controllers/projects_controller.rb and defines the
ProjectsController constant that your test needs. This controller is where
all the actions will live, just like app/controllers/purchases_controller.rb
back in chapter 1. Here’s what this command outputs:
create app/controllers/projects_controller.rb invoke erb create app/views/projects invoke rspec create spec/requests/projects_spec.rb invoke helper create app/helpers/projects_helper.rb invoke rspec create spec/helpers/projects_helper_spec.rb
Before we dive into that, a couple of notes about the output.
-
app/views/projectscontains the views relating to your actions (more on this shortly). -
invoke helpershows that thehelpergenerator was called here, generating a file atapp/helpers/projects_helper.rb. This file defines aProjectsHelpermodule. Helpers generally contain custom methods to use in your view that help with the rendering of content, and they come as blank slates when they’re first created. -
invoke erbsignifies that the Embedded Ruby (ERB) generator was invoked. Actions to be generated for this controller have corresponding ERB views located inapp/views/projects. For instance, theindexaction’s default view will be located atapp/views/projects/index.html.erbwhen we create it later on. -
invoke rspecshows that the RSpec generator was also invoked during the generation. This means RSpec has generated a new file atspec/helpers/projects_helper.rb, which you can use to test your helper—but not right now.[5]
You’ve just run the generator to generate a new ProjectsController class and
all its goodies. This should fix the "uninitialized constant" error message.
If you run bundle exec rspec again, it declares that the index action is missing:
1) Users can create new projects with valid attributes
Failure/Error: visit "/"
AbstractController::ActionNotFound:
The action 'index' could not be found for ProjectsController
Defining a controller action
To define the index action in your controller,
you must define a method in the ProjectsController class, just as
you did when you generated your first application, as shown in the following listing.
class ProjectsController < ApplicationController
def index
end
endIf you run bundle exec rspec again, this time Rails complain
of a missing template projects/index:
1) Users can create new projects with valid attributes
Failure/Error: visit "/"
ActionController::MissingExactTemplate:
ProjectsController#index is missing a template for request formats: text/html
This error says that we’re missing a template for the request format of text/html. This means that we will need to create a view.
To generate this view, create the app/views/projects/index.html.erb file
and leave it blank for now. This file is called index.html.erb so that we have the correct format (HTML), and this file will be using ERB to evaluate some Ruby to generate some of that HTML, hence the .erb extension.
Let’s run this test one more time:
1) Users can create new projects with valid attributes
Failure/Error: click_link "New Project"
Capybara::ElementNotFound:
Unable to find link "New Project"
You’ve defined a home page for your application by defining a root route, generating a controller, putting an action in it, and creating a view for that action. Now Capybara is successfully navigating to it, and rendering it. That’s the first step in the first test passing for your first application, and it’s a great first step!
The second line in your spec is now failing, and it’s up
to you to fix it. You need a link on the root page of your application that reads "New
Project". That link should go in the view of the controller that’s serving the root route
request: app/views/projects/index.html.erb. Create a new file at app/views/projects/index.html.erb and open it for editing. Put the "New Project" link in by using the link_to method:
<%= link_to "New Project", new_project_path %>This single line reintroduces two old concepts and a new one: ERB output
tags, the link_to method (both of which you saw in chapter 1), and the
mysterious new_project_path method.
As a refresher, in ERB, when you use <%= (known as an ERB output tag),
you’re telling ERB that whatever the output of this Ruby is, put it on the
page. If you only want to evaluate Ruby, you use an ERB evaluation tag <%,
which doesn’t output content to the page but only evaluates it. Both of these
tags end in %>.
The link_to method in Rails generates an <a> tag with the text of the first
argument and the href of the second argument. This method can also be used in block format if
you have a lot of text you want to link to:
<%= link_to new_project_path do %>
bunch
of
text
<% end %>Where new_project_path comes from deserves its own section. It’s the very
next one.
RESTful routing
The new_project_path method is as yet undefined. If you ran the test again,
it would complain of an "undefined local variable or method
'new_project_path'". You can define this method by defining a route to what’s
known as a resource in Rails. Resources are collections of objects that all
belong in a common location, such as projects, users, or tickets. You can add
the projects resource in config/routes.rb by using the resources method,
putting it directly under the root method in this file.
resources :projects line in config/routes.rbRails.application.routes.draw do
root "projects#index"
resources :projects
endThis is called a resource route, and it defines
the routes to the seven RESTful actions in your ProjectsController.
We saw this method used back in Chapter 1, except then it generated routes to the actions in PurchasesController.
When something is said to be RESTful, it means it conforms to Rails' interpretation of the Representational State Transfer (REST) architectural style.[6]
With Rails, this means the related controller has seven potential actions:
-
index -
show -
new -
create -
edit -
update -
destroy
These seven actions match to just four request paths:
-
/projects -
/projects/new -
/projects/:id -
/projects/:id/edit
How can four be equal to seven? It can’t! Not in this world, anyway. Rails will determine what action to route to on the basis of the HTTP method of the requests to these paths. We can see this if we run this command:
rails routes -c projects
This command will show us the routes that are defined for the ProjectsController:
| Prefix | Verb | URI Pattern | Controller#Action |
|---|---|---|---|
projects |
GET |
/projects |
projects#index |
POST |
/projects |
projects#create |
|
new_project |
GET |
/projects/new |
projects#new |
edit_project |
GET |
/projects/:id/edit |
projects#edit |
project |
GET |
/projects/:id |
projects#show |
PATCH |
/projects/:id |
projects#update |
|
PUT |
/projects/:id |
projects#update |
|
DELETE |
/projects/:id |
projects#destroy |
The routes listed in the table are provided when you use resources :projects. This
is yet another great example of how Rails takes care of the configuration so you can take care of the coding.
The words in the leftmost column of this output are the beginnings of the
method names you can use in your controllers or views to access them. If you
want just the path to a route, such as /projects, then use projects_path. If
you want the full URL, such as http://yoursite.com/projects, use
projects_url. It’s best to use these helpers rather than hard-coding the
URLs; doing so makes your application consistent across the board. For
example, to generate the route to a single project, you would use either
project_path or project_url:
project_path(@project)This method takes one argument, shown in the URI pattern with the :id notation,
and generates the path according to this object. If the id attribute for @project was 1, then the path this method would generate is /projects/1.
Running bundle exec rspec now produces a complaint about a missing new action:
1) Users can create new projects with valid attributes
Failure/Error: click_link "New Project"
AbstractController::ActionNotFound:
The action 'new' could not be found for ProjectsController
As shown in the following listing, define the new
action in your controller by defining a new method directly
underneath the index method.
class ProjectsController < ApplicationController
def index
end
def new
end
endRunning bundle exec rspec now results in a complaint about a missing new template,
just as it did with the index action:
1) Users can create new projects with valid attributes
Failure/Error: click_link "New Project"
ActionController::MissingExactTemplate:
ProjectsController#new is missing a template for request formats: text/html
You can create the file at app/views/projects/new.html.erb to make this
test go one step further, although this is a temporary solution. You’ll come back to this
file later to add content to it. When you run the spec again, the line that should be
failing is the one regarding filling in the "Name" field. Find out if this is the case by
running bundle exec rspec:
1) Users can create new projects with valid attributes
Failure/Error: fill_in "Name", with: "Visual Studio Code"
Capybara::ElementNotFound:
Unable to find field "Name"
Now Capybara is complaining about a missing "Name" field on the page it’s
currently on, the new page. You must add this field so that Capybara can fill
it in. Before you do that, however, fill out the new action in the
ProjectsController like the following.
def new
@project = Project.new
endWhen we fill out the view with the fields we need to create a new project, we’ll
need something to base the fields on - an instance of the class we want to create.
This Project constant will be a class, located at app/models/project.rb,
thereby making it a model.
Of models and migrations
A model is used to perform queries on a database, to fetch or store information. Because models by default inherit from Active Record, you don’t have to set up anything extra. Run the following command to generate your first model:
$ rails g model project name description
This syntax is similar to the controller generator’s
syntax except that you specified you want a model, not a controller. When the
generator runs, it generates not only the model file but also a migration
containing the code to create the table for the model, containing the specified fields. You can
specify as many fields as you like after the model’s name. They default to
string type, so you didn’t need to specify them. If you wanted to be explicit, you
could use a colon followed by the field type, like this:
$ rails g model project name:string description:string
A model provides a place for any business logic that your application does. One common bit of logic is the way your application interacts with a database. A model is also the place where you define validations (seen later in this chapter), associations (discussed in chapter 5) and scopes (easy-to-use filters for database calls, discussed in chapter 7), among other things. To perform any interaction with data in your database, you go through a model.[7]
Migrations are effectively version control for the database. They’re defined
as Ruby classes, which allows them to apply to multiple database schemas
without having to be altered. All migrations have a change method in them
when they’re first defined. For example, the code shown in the following
listing comes from the migration that was just generated.
class CreateProjects < ActiveRecord::Migration[7.0]
def change
create_table :projects do |t|
t.string :name
t.string :description
t.timestamps
end
end
endWhen you run the migration forward (using bundle exec rails
db:migrate), it creates the table in the database. When you roll the migration back (with
rails db:rollback), it deletes (or drops) the table from the
database. If you need to do something different on the up and down parts, you can use those
methods instead:
up and down methods to define a migrationclass CreateProjects < ActiveRecord::Migration[7.0]
def up
create_table :projects do |t|
t.string :name
t.string :description
t.timestamps
end
end
def down
drop_table :projects
end
endHere, the up method would be called if
you ran the migration forward, and the down method would be
run if you ran it backward.
This syntax is especially helpful if the migration does something that has a reverse function that isn’t clear, such as removing a column[8]:
class CreateProjects < ActiveRecord::Migration[7.0]
def up
remove_column :projects, :name
end
def down
add_column :projects, :name, :string
end
endThis is because Active Record won’t know what type of field to re-add this column as, so you must tell it what to do in the case of this migration being rolled back.
In our projects migration, the first line of the change method tells Active
Record that you want to create a table called
projects. You call this method using the block format, which returns an object
that defines the table. To add fields to this table, you call methods on the
block’s object (called t in this example and in all model migrations), the
name of which usually reflects the type of column it is; the first argument is
the name of that field. The timestamps method is special: it creates two
fields, created_at and updated_at, which are by default
set to the current time in co-ordinated universal time (UTC)[9]
by Rails when a record is created and updated, respectively.
A migration doesn’t automatically run when you create it—you must run it yourself using this command:
$ rails db:migrate
These commands migrate the database up to the latest migration, which for
now is the only migration. If you create a whole slew of migrations at once, then invoking
rails db:migrate will migrate them in the order in
which they were created. This is the purpose of the timestamp in the migration
filename - to keep the migrations in chronological order.
With this model created and its related migration run, your test doesn’t get any further but you can start building out the form to create a new project.
Form building
To add this field to the new action’s view, you can put it in a form, but
not just any form: a form_with, as in the following listing.
<h1>New Project</h1>
<%= form_with(model: @project) do |form| %>
<div>
<%= form.label :name %>
<%= form.text_field :name %>
</div>
<div>
<%= form.label :description %>
<%= form.text_field :description %>
</div>
<%= form.submit %>
<% end %>So many new things!
Starting at the top, the form_with method is Rails' way of building forms for
Active Record objects. You pass it the @project object you defined in your controller as the argument for the model option and with this, the helper does much more than simply place a form tag on the page. form_with inspects the @project object and creates a form builder
specifically for that object. The two main things it inspects are whether it’s
a new record and what the class name is.
Determining what action attribute the form has (the URL the form submits its data to)
depends on whether the object is a new record or not. A record is classified as new
when it hasn’t been saved to the database. This check is performed internally
by Rails using the persisted? method, which returns true if the record is
stored in the database or false if it’s not.
The class of the object also plays a pivotal role in where the form is sent -
Rails inspects this class and,
from it, determines what the route should be. Because @project is new and is
an object of class Project, Rails determines that the submit URL will be the result of projects_path, which will mean the route is /projects and the method for the form is POST. Therefore, a request is sent to the create action in ProjectsController.
If we were to look at the form’s generated HTML, we would see this:
<form action="/projects" accept-charset="UTF-8" method="post">The action and method in combination will make this form submit to POST /projects, sending the form’s data to the create action within ProjectsController.
After that part of form_with is complete, you use the block syntax to receive
a form variable, which is a FormBuilder object. You can use this object to
define your form’s fields. The first element you define is a label. label tags directly relate to the input fields on the page
and serve two purposes. First, they give users a larger
area to click, rather than just the field, radio button, or check box. The
second purpose is so you can reference the label’s text in the test, and
Capybara will know what field to fill in.
|
Alternative label naming
By default, the label’s text value will be the 'humanized' value of the field name, eg.
|
After the label, you put the text_field,
which renders an <input> tag corresponding to the label and the field. The
output tag looks like this:
<input type="text" name="project[name]" id="project_name" />Then you use the submit method to provide users with a submit button for
your form. Because you call this method on the form object, Rails checks
whether the record is new and sets the text to read "Create Project" if the
record is new or "Update Project" if it isn’t. You’ll see this in use a little
later when you build the edit action. For now, focus on the new action!
Now, running bundle exec rspec once more, you can see that your spec is
one step closer to finishing—the field fill-in steps have passed:
1) Users can create new projects with valid attributes
Failure/Error: click_button "Create Project"
AbstractController::ActionNotFound:
The action 'create' could not be found for ProjectsController
Capybara finds the label containing the "Name" text you ask for in your
scenario, and fills out the corresponding field with the value we specify. Capybara has a number of ways
to locate a field, such as by the name of the corresponding label, the id
attribute of the field, or the name attribute. The last two look like this:
fill_in "project_name", with: "Visual Studio Code"
# or
fill_in "project[name]", with: "Visual Studio Code"|
Should we use the ID or the label?
Some argue that using the field’s ID or name is a better way because these attributes don’t change as often as labels may. But your tests should aim to be as human-readable as possible - when you write them, you don’t want to be thinking of field IDs, you’re describing the behavior at a higher level than that. To keep things simple, you should continue using the label name. |
Capybara does the same thing for the "Description" field, and then will click the
button we told it to click. The spec is now complaining about a missing action called create. Let’s fix that.
Creating the create action
To define this action, you define the create method underneath the new method in the
ProjectsController, as in the following listing.
create action of ProjectsController
def create
@project = Project.new(project_params)
if @project.save
flash[:notice] = "Project has been created."
redirect_to @project
else
# nothing, yet
end
endThe Project.new method takes one argument, which is a list of attributes
that will be assigned to this new Project object. For now, we’re just calling that
list project_params.
After you build your new @project instance, you call @project.save to save it
to the projects table in your database. Before that happens, though, Rails will run all the data validations on
the model, ensuring that it’s valid. At the moment, you have no validations
on the model, so it will save just fine.
The flash method in your create action is a way of passing
messages to the next request, and it takes the form of a hash.
These messages are stored in the session and are cleared at the completion of
the next request. Here you set the :notice key of the flash hash to be "Project has been
created" to inform the user what has happened. This message is displayed
later, as is required by the final step in your feature.
The redirect_to method can take several different arguments - an object, or
the name of a route. If an object is given, Rails inspects it to
determine what route it should go to: in this case, project_path(@project)
because the object has now been saved to the database. This method generates
the path of something such as /projects/:id, where :id is the record’s id
attribute assigned by your database system. The redirect_to method tells
the browser to begin making a new request to that path and sends back an empty
response body; the HTTP status code will be a "302 Redirect", and point to
the currently non-existent show action.
|
Combining redirect_to and flash
You can combine If you don’t wish to use either |
If you run bundle exec rspec now, you’ll get an error about an undefined local variable or method
"project_params".
1) Users can create new projects with valid attributes
Failure/Error: @project = Project.new(project_params)
NameError:
undefined local variable or method `project_params' for #<ProjectsController:0x0000000000bba8>
@project = Project.new(project_params)
^^^^^^^^^^^^^^
Did you mean? project_path
Where does the data we want to make a new project from, come from? They
come from the params provided to the controller, available to all Rails controller actions.
The params method returns the parameters passed to the action, such as those from the form
or query parameters from a URL, as a
HashWithIndifferentAccess object. These
are different from normal Hash objects, because you can reference a String
key by using a matching Symbol and vice versa. In this case, the params
hash looks like this:
{
"authenticity_token" => "WRHnKqU...",
"project" => {
"name" => "Visual Studio Code",
"description" => "Code Editing. Redefined."
},
"commit" => "Create Project",
"controller" => "projects",
"action" => "create"
}You can easily see what params your controller is receiving by looking at the server
logs in your terminal console. If you run your rails server, visit http://localhost:3000/projects/new
and submit the data that your test is trying to submit, you’ll see the following in the terminal:
Started POST "/projects" for ::1 at [timestamp]
Processing by ProjectsController#create as HTML
Parameters: {"authenticity_token"=>"WRHnKqU...",
"project"=>{"name"=>"Visual Studio Code", "description"=>"A text editor
for everyone"}, "commit"=>"Create Project"}
And the parameters are listed right there.
|
The authenticity_token` parameter
There’s a "special" parameter in the The |
All the hashes nested inside the params hash are also HashWithIndifferentAccess
hashes. If you want to get the name key from the project hash here, you can
use either { :name ⇒ "Visual Studio Code" }[:name], as in a normal Hash
object, or { :name ⇒ "Visual Studio Code" }['name']; you may use either the
String or the Symbol version—it doesn’t matter.
The first key in the params hash, commit, comes from the submit button of the form,
which has the value "Create Project". This is accessible as
params[:commit]. The second key, action, is one of two parameters always
available; the other is controller. These represent exactly what their names
imply: the controller and action of the request, accessible as
params[:controller] and params[:action], respectively. The final key,
project, is, as mentioned before, a HashWithIndifferentAccess. It contains
the fields from your form and is accessible via params[:project]. To access
the name key in the params[:project] object, use
params[:project][:name], which calls the [] method on params to get the
value of the :project key and then, on the resulting hash, calls [] again,
this time with the :name key to get the name of the project passed in.
params[:project] has all the data we need to pass to Project.new, but we can’t
just pass it directly in. If you try to substitute project_params with params[:project]
in your controller, and then run rspec again, you’ll get the following error:
Failure/Error: click_button "Create Project" ActiveModel::ForbiddenAttributesError: ActiveModel::ForbiddenAttributesError
Strong parameters
Oooh, forbidden attributes. Sounds scary. This is important: it’s one form of security help that Rails gives you via a feature called strong parameters. You don’t want to accept just any submitted parameters: you want to accept the ones that you want and expect, and no more. That way, someone can’t mess around with your application by doing things like tampering with the form and adding new fields, before submitting it.
Change the ProjectsController code to add a new definition for the project_params method.
def create
@project = Project.new(project_params)
if @project.save
flash[:notice] = "Project has been created."
redirect_to @project
else
# nothing, yet
end
end
private
def project_params
params.require(:project).permit(:name, :description)
endYou now call the require method on your params, and you require that the
:project key exists. You also allow it to have :name and :description
entries - any other fields submitted will be discarded. Finally, you wrap up that logic
into a method so you can use it in
other actions, and you make it private so you don’t expose it as some kind of
weird action! We’ll use this method in one other action in this controller
later on, the update action.
With that done, run bundle exec rspec again, and you’ll get a new error:
1) Users can create new projects with valid attributes
Failure/Error: click_button "Create Project"
AbstractController::ActionNotFound:
The action 'show' could not be found for ProjectsController
The test has made it through the create action, followed the redirect we
issued, and now it’s stuck on the next request - the page we redirected to,
the show action.
The show action is responsible for displaying a single record’s information.
Retrieving a record to display is done by default using the record’s ID. You know the URL for this page
will be something like /projects/1, but how do you get the 1 from that URL?
Well, when you use resource routing, as you have done already, the 1 part of
this URL is available as params[:id], just as params[:controller] and
params[:action] are also automatically made available by Rails. You can then
use this params[:id] parameter in your show action to find a specific
Project object. In this case, the show action should be showing the newly
created project.
Put the code from the following listing into
app/controllers/projects_controller.rb to set up the show action. Make sure
it comes above the private declaration, or you won’t be able to use it as an
action!
show action of ProjectsController
def show
@project = Project.find(params[:id])
endYou pass the params[:id] object to Project.find. This gives you a single
Project object that relates to a record in the database, which has its id
field set to whatever params[:id] is. If Active Record can’t find a record
matching that ID, it raises an ActiveRecord::RecordNotFound
exception.
When you rerun bundle exec rspec spec/features/creating_projects_spec.rb, you’ll
get an error telling you that the show action’s template is missing:
1) Users can create new projects with valid attributes
Failure/Error: click_button "Create Project"
ActionController::MissingExactTemplate:
ProjectsController#show is missing a template for request formats: text/html
You can create the file app/views/projects/show.html.erb with the following
content for now to display the project’s name and description:
<h1><%= @project.name %></h1>
<p><%= @project.description %></p>It’s a pretty plain page for a project, but it will serve our purpose.
When you run the test again with bundle exec rspec spec/features/creating_projects_spec.rb,
you see this message:
1) Users can create new projects with valid attributes
Failure/Error: expect(page).to have_content "Project has been created."
expected to find text "Project has been created." in "Visual Studio Code\nCode Editing. Redefined"
This error message shows that the "Project has been created." text isn’t being displayed on the page. Therefore, you must put it somewhere, but where?
The application layout
The best location is in the application layout, located at
app/views/layouts/application.html.erb. This file provides the layout for
all templates in your application, so it’s a great spot to output a flash
message - no matter what controller we set it in, it will be rendered on the
page.
The application layout is quite the interesting file:
<!DOCTYPE html>
<html>
<head>
<title>Ticketee</title>
<meta name="viewport" content="width=device-width,initial-scale=1">
<%= csrf_meta_tags %>
<%= csp_meta_tag %>
<%= stylesheet_link_tag "application", "data-turbo-track": "reload" %>
<%= javascript_importmap_tags %>
</head>
<body>
<%= yield %>
</body>
</html>The first line sets up the doctype to be HTML for the layout, and three new
methods are used: stylesheet_link_tag, javascript_importmap_tags, and
csrf_meta_tags.
The stylesheet_link_tag and javascript_importmap_tags methods include CSS and JavaScript assets for our application.
The csrf_meta_tags is for protecting your forms from cross-site request forgery
(CSRF[10]) attacks. These types of attacks were
mentioned a short while ago when we looked at the parameters for the create
action; when we were talking about the authenticity_token parameter. The csrf_meta_tags helper creates two meta tags, one called csrf-param and the other csrf-token. This unique token works by setting a
specific key on forms that is then sent back to the server. The server checks
this key, and if the key is valid, the form is deemed valid. If the key is
invalid, an ActionController::InvalidAuthenticityToken exception occurs and
the user’s session is reset as a precaution.
Later in app/views/layouts/application.html.erb is the single line:
<%= yield %>This line indicates to the layout where the current action’s template is
to be rendered. Create a new line just before <%= yield %>,
and place the following code there:
<% flash.each do |key, message| %>
<div><%= message %></div>
<% end %>This code renders all the flash messages
that are defined, regardless of their name and the controller they come from.
These lines will display the flash[:notice] that you set up in the create action of the
ProjectsController. Run bundle exec rspec again, and see that
the test is now fully passing:
4 examples, 0 failures, 3 pending
Why do you have three pending tests? If you examine the output more closely, you’ll see this:
.***
1) ProjectsHelper add some examples to (or delete)
# Not yet implemented
# ./spec/helpers/projects_helper_spec.rb:14
2) Project add some examples to (or delete)
# Not yet implemented
# ./spec/models/project_spec.rb:4
3) Projects GET /index add some examples (or delete)
# Not yet implemented
# ./spec/requests/projects_spec.rb:5
The key part is that "or delete". Let’s delete those two files, because you’re not using them yet:
$ rm spec/models/project_spec.rb $ rm spec/helpers/projects_helper_spec.rb $ rm spec/requests/projects_spec.rb
Afterward, run bundle exec rspec one more time:
. Finished in 0.07521 seconds (files took 1.25 seconds to load) 1 example, 0 failures
Yippee! You have just written your first BDD test for this application! That’s all there is to it. If this process feels slow, that’s how it’s supposed to feel when you’re new to anything. Remember when you were learning to drive a car? You didn’t drive like Michael Schumacher as soon as you got behind the wheel. You learned by doing it slowly and methodically. As you progressed, you were able to do it more quickly, as you can all things with practice.
Committing changes
Now you’re at a point where all (just the one for now) your specs are running. Points like this are great times to make a commit:
$ git add . $ git commit -m "'Create a new project' feature complete."
You should commit often, because commits provide checkpoints you can revert back to if anything goes wrong. If you’re going down a path where things aren’t working, and you want to get back to the last commit, you can safely store all your changes by running:
$ git stash
Then you can re-apply those changes if you wish with:
$ git stash pop
If you want to completely forget about those changes and remove them, use:
$ git checkout
|
Use
git checkout . carefully!This command doesn’t prompt you to ask whether you’re sure you want to take
this action. You should be incredibly sure that you want to destroy your
changes. If you’re not sure and want to keep your changes while reverting back
to the previous revision, it’s best to use the |
With the changes committed to your local repository, you can push them off to the GitHub servers. If for some reason the code on your local machine goes missing, you have GitHub as a backup. Run this command to push the code up to GitHub’s servers:
$ git push
Commit early. Commit often.
Setting a page title
Before you completely finish working with this story, there is one more thing
to point out: the templates (such as show.html.erb) are rendered before the layout. You can use this
to your benefit by setting an instance variable such as @title in the show
action’s template; then you can reference it in your application’s layout to
show a title for your page at the top of the tab or window.
To test that the page title is correctly implemented, add a little bit extra
to your scenario for it. At the bottom of the test in
spec/features/creating_projects_spec.rb, add these four lines:
project = Project.find_by!(name: "Visual Studio Code")
expect(page.current_url).to eq project_url(project)
title = "Visual Studio Code - Projects - Ticketee"
expect(page).to have_title titleThe first line here uses the find_by! method to find a project by its name.
This finds the project that has just been created by the code directly above it.
If the project cannot be found, an exception will be raised: an
ActiveRecord::RecordNotFound exception. If you see one of these, make sure
both places where you’re using your project’s name are the same name.
The second line ensures that you’re on what should be the show action in
the ProjectsController. The third and fourth lines finds the title element on the page
by using Capybara’s find method and checks using have_title that
this element contains the page title of "Visual Studio Code - Projects - Ticketee". If
you run bundle exec rspec spec/features/creating_projects_spec.rb now, you’ll
see this error:
1) Users can create new projects with valid attributes
Failure/Error: expect(page).to have_title title
expected "Ticketee" to include "Visual Studio Code - Projects -
Ticketee"
This error is happening because the title element doesn’t contain all the
right parts, but this is fixable! Write this code into the top of
app/views/projects/show.html.erb:
<% @title = "Visual Studio Code - Projects - Ticketee" %>This sets up a @title instance variable in the template. Because the
template is rendered before the layout, you’re able to then use this variable
in the layout. But if a page doesn’t have a @title variable set, there
should be a default title of "Ticketee". To do this, enter the following code in
app/views/layouts/application.html.erb where the <title> tag currently is, inside the <head> tag of the page:
<title><%= @title || "Ticketee" %></title>In Ruby, instance variables that aren’t set return nil as their value. If you
try to access an instance variable that returns a nil value, you can use || to return a
different value, as in this example.
With this in place, the test should pass when you run bundle exec rspec:
1 example, 0 failures
Now that this test passes, you can change your code and have a solid base to
ensure that whatever you change works as you expect. To demonstrate this
point, you’ll change the code in show to use a helper instead of setting a
variable.
Helpers are methods you can define in the files in app/helpers, and they’re
made available in your views. Helpers are for extracting the logic from the
views; views should just be about displaying information. Every controller
that comes from the controller generator has a corresponding helper, and
another helper module exists for the entire application: the
ApplicationHelper module, that lives at app/helpers/application_helper.rb.
Open app/helpers/application_helper.rb, and insert the code from the
following listing.
module ApplicationHelper
def set_title(*parts)
unless parts.empty?
content_for :title do
(parts << "Ticketee").join(" - ")
end
end
end
endWhen you specify an argument in a method beginning with the splat operator
(*), any arguments passed from this point will be available in the method
as an array. Here that array can be referenced as parts. Inside the
method, you check to see if parts is empty? by using keyword that’s
the opposite of if: unless. If no arguments are passed to the
set_title method, parts will be empty and therefore empty? will return
true.
If parts are specified for the set_title method, then you use the content_for
method to define a named block of content, giving it the name "title".
Inside this content block, you join the parts together using a hyphen (-),
meaning this helper will output something like "Visual Studio Code - Projects -
Ticketee".
So this helper method will build up a text string that we can use as the title of any page, including the default value of "Ticketee", and all we need to do it call it from the view with the right arguments - an array of the parts that will make up the title of the page. Neat.
Now you can replace the title line in app/views/projects/show.html.erb
with this:
<% set_title @project.name, "Projects" %>Let’s replace the title tag line in app/views/layouts/application.html.erb
with this code:
<title>
<%= content_for(:title) || "Ticketee" %>
</title>This code uses the non-block version of content_for, which will output the stored value, if one is present. It will return nil otherwise, and if it does that then "Ticketee" will be displayed as the title.
When you run this test again with bundle exec rspec spec/features/creating_projects_spec.rb,
it will still pass:
1 example, 0 failures
That’s a lot neater, isn’t it? Let’s create a commit for that functionality and push your changes:
$ git add . $ git commit -m "Add title functionality for project show page" $ git push
Next up, we look at how to stop users from entering invalid data into your forms.
Validations
The next problem to solve is preventing users from leaving a required field blank. A project with no name isn’t useful to anybody. Thankfully, Active Record provides validations for this issue. Validations are run just before an object is saved to the database, and if the validations fail, then the object isn’t saved. Ideally, in this situation, you want to tell the user what went wrong so they can fix it and attempt to create the project again.
We saw validations back in Chapter 1 too: we validated that a purchase had to have a name, as well as a cost that was above 0. In this chapter, we’ll just validate that a project’s name is present.
With this in mind, let’s add another test for ensuring that this happens to
spec/features/creating_projects_spec.rb using the code from the next listing.
scenario "when providing invalid attributes" do
visit "/"
click_link "New Project"
click_button "Create Project"
expect(page).to have_content "Project has not been created."
expect(page).to have_content "Name can't be blank"
endThe first two lines are identical to the ones you placed in the other scenario. You should eliminate this duplication by making your code DRY (Don’t Repeat Yourself!). This is another term you’ll hear a lot in the Ruby world.[11] It’s easy to extract common code from where it’s being duplicated, and into a method or a module you can use instead of the duplication. One line of code is 100 times better than 100 lines of duplicated code.
To DRY up your code, before the first scenario, you can define a before
block. For RSpec, before blocks are run before every test in the file.
Change spec/features/creating_projects_spec.rb to
look like this.
require "rails_helper"
RSpec.feature "Users can create new projects" do
before do
visit "/"
click_link "New Project"
end
scenario "with valid attributes" do
fill_in "Name", with: "Visual Studio Code"
fill_in "Description", with: "Code Editing. Redefined"
click_button "Create Project"
expect(page).to have_content "Project has been created."
project = Project.find_by(name: "Visual Studio Code")
expect(page.current_url).to eq project_url(project)
title = "Visual Studio Code - Projects - Ticketee"
expect(page).to have_title title
end
scenario "when providing invalid attributes" do
click_button "Create Project"
expect(page).to have_content "Project has not been created."
expect(page).to have_content "Name can't be blank"
end
endThere! That looks a lot better! Now when you run bundle exec rspec, it will fail because
it can’t see the error message that it’s expecting to see on the page:
1) Users can create new projects when providing invalid attributes
Failure/Error: expect(page).to have_content "Project has not been
created."
expected to find text "Project has not been created." in "Project
has been created."
Adding validations
To get this test to do what you want it to do, you’ll need to add a
validation. Validations are defined on the model and are run before the data
is saved to the database. To define a validation to ensure that the name
attribute is provided when a project is created, open the
app/models/project.rb file and make it look like the following listing.
class Project < ApplicationRecord
validates :name, presence: true
endThe validates method’s usage is exactly how you
used it for the first time in chapter 1. It tells the model that you want to
validate the name field, and that you want to validate its presence. There
are other kinds of validations as well; for example, the
:uniqueness key, when passed true as the
value, validates the uniqueness of this field as well, ensuring that only one
record in the table has that specific value.[12]
With the presence validation in place, you can experiment with the
validation by using the Rails console, which allows you to have all the classes and the
environment from your application loaded in a sandbox environment. You can launch the
console with this command:
$ rails console
or with its shorter alternative:
$ rails c
If you’re familiar with Ruby, you may realize that this is effectively IRB with some Rails sugar on top. For those of you new to both, IRB stands for Interactive Ruby, and it provides an environment for you to experiment with Ruby without having to create new files. The console prompt looks like this:
Loading development environment (Rails 6.1.0) irb(main):001:0>
At this prompt[13], you can enter any valid Ruby, and
it’ll be evaluated. But for now, the purpose of opening this console was to
test the newly appointed validation. To do this, try to create a new project
record by calling the create method. The create method is similar to the
new method, but it attempts to create an object and then a database record
for it rather than just the object. You use it identically to the new
method:
irb(main):001:0> Project.create
=> #<Project id: nil, name: nil, description: nil, created_at: nil,
updated_at: nil>
Here you get a new Project object with
the name and description attributes set to nil, as you should expect
because you didn’t specify it. The id attribute is nil too, which
indicates that this object isn’t persisted (saved) in the database.
If you comment out or remove the validation from in the Project class and type reload! in your
console, the changes you just made to the model are reloaded. When the validation is
removed, you have a slightly different outcome when you call Project.create:
irb(main):001:0> Project.create
=> #<Project id: 1, name: nil, description: nil,
created_at: [timestamp], updated_at: [timestamp]>
Here, the name field is still expectedly nil, but the other three
attributes have values. Why? When you call create on the Project model,
Rails builds a new Project object with any attributes you pass
it[14] and checks to see if that object is valid. If it is, Rails
sets the created_at and
updated_at attributes to the current time and then
saves the object to the database. After it’s saved, the id is returned from
the database and set on your object. This object is valid, according to Rails,
because you removed the validation, and therefore Rails goes through the
entire process of saving.
The create method has a bigger, meaner brother called create! (pronounced create BANG!). Re-add or uncomment the validation from the model, and type reload! in the console, and you’ll see what this mean variant does with this line:
irb(main):001:0> Project.create! ActiveRecord::RecordInvalid: Validation failed: Name can't be blank
The create! method, instead of nonchalantly handing back a Project object
regardless of any validations, raises an ActiveRecord::RecordInvalid
exception if any of the validations fail; it shows the exception followed by a
large stacktrace, which you can safely ignore for now. You’re notified which
validation failed. To stop it from failing, you must pass in a name
attribute, and create will happily return a saved Project object:
irb(main):002:0> Project.create!(name: "Visual Studio Code")
=> #<Project id: 2, name: "Visual Studio Code", description: nil,
created_at: [timestamp], updated_at: [timestamp]>
That’s how to use create to test your validations in the console. We’ve created
some bad data in our database during our experimentation, we should clean that
up before we continue.
irb(main):003:0> Project.delete_all => 2
Back in your ProjectsController, we’re using the method shown in the following
listing instead.
create action of ProjectsController
def create
@project = Project.new(project_params)
if @project.save
...If the validations pass, save here will return true.
You can use this to your advantage to show the user an error message when this
returns false by using it in an if statement. Make the create action in
the ProjectsController look like the following listing.
create action from ProjectsController
def create
@project = Project.new(project_params)
if @project.save
flash[:notice] = "Project has been created."
redirect_to @project
else
flash.now[:alert] = "Project has not been created."
render "new"
end
end
flash vs. flash.now
The above controller action uses two different methods to access the array of
flash messages for your page -
There’s also a third method - If you were to use |
Now, if the @project object has a name attribute — meaning it’s valid — save
returns true and executes everything between if and else. If it isn’t
valid, then everything between else and the following end is executed. In
the else, you specify a different key for the flash message because you’ll
want to style alert messages differently from notices later in the
application’s lifecycle. When good things happen, the messages for them will
be colored with a green background. When bad things happen, red.
When you run bundle exec rspec spec/features/creating_projects_spec.rb here, the
line in the spec that checks for the "Project has not been created." message
now doesn’t fail; so, it goes to the next line, which checks for the "Name
can’t be blank" message. You haven’t done anything to make this message appear
on the page right now, which is why the test is failing again:
1) Users can create new projects when providing invalid attributes
Failure/Error: expect(page).to have_content "Name can't be blank"
expected to find text "Name can't be blank" in "Project has not
been created. New Project Name Description"
The validation errors for the project aren’t being displayed on this page, which is causing the test to fail. To display validation errors in the view, you need to code something up yourself.
When an object fails validation, Rails will populate the errors of the object
with any validation errors. You can test this back in your Rails console:
irb(main):001:0> project = Project.create
=> #<Project id: nil, name: nil, description: nil, created_at: nil,
updated_at: nil>
irb(main):002:0> project.errors
=> #<ActiveModel::Errors:0x007fd5938197f8 @base=#<Project id: nil,
name: nil, description: nil, created_at: nil, updated_at: nil>,
@messages={:name=>["can't be blank"]}>
ActiveModel::Errors provides some nice helper methods for working with the
validation errors, that we can use in our views to display the errors back to
the user. Directly under this form_with line, on a new
line, insert the following into app/views/projects/new.html.erb to display the error
messages in the form.
<%= form_with(model: @project) do |form| %>
<% if @project.errors.any? %>
<div id="error_explanation">
<h2><%= pluralize(@project.errors.count, "error") %>
prohibited this project from being saved:</h2>
<ul>
<% @project.errors.full_messages.each do |msg| %>
<li><%= msg %></li>
<% end %>
</ul>
</div>
<% end %>
...
<% end %>Error messages for the object represented by your form, the @project object,
will now be displayed by each. When you run bundle exec rspec, you get this
output:
2 examples, 0 failures
Commit and push, and then you’re done with this story!
$ git add . $ git commit -m "Add validation to ensure names are specified when creating projects" $ git push
Takeaways
Behavior Driven Development
Behavior Driver Development is the process of writing tests asserting that our application will have certain behaviour, before we write code. These tests provide us with an automated way of testing our application, providing constant assurances that our application is working as it should.
Some people might argue that this is extra work; that it isn’t contributing anything valuable. We disagree. Having a quick, automatic way to ensure that the application is working as intended throughout the application’s life is extremely valuable. It prevents mistakes that may change the behaviour of the application from being introduced.
An application with tests, is more maintainable than an application without.
Version Control
In this chapter, we have used Git throughout to store our code’s changes.
This allows us to have checkpoints where our code is at known-working states where all our tests are passing. These are valuable, because it helps break our work into small atomic chunks.
Further to this, if we happen to develop down the wrong path long enough and discover that later on, we can run git checkout . to reset our code back to the latest known-working state
You can build Rails apps without scaffold
In Chapter 1, we used the scaffold generator to quickly build a part of our application. However, this is not how Rails developers do it in the real world.
In the real world, Rails developers write tests, and then incrementally build up their features as we’ve seen in this chapter. As you practice this technique, you will get faster at it. For example, you’ll know that if you have a route that you’ll need a controller and an action to go along with that. You might just go ahead and build those, rather than waiting for your tests to tell you that those are needed.
While the scaffold generator gives you a lot, we can take the training wheels off now and develop our application without relying on Rails to do it for us.
Summary
We first covered how to version-control an application, which is a critical part of the application development cycle. Without proper version control, you’re liable to lose valuable work or be unable to roll back to a known working stage. We used Git and GitHub as examples, but you may use an alternative—such as SVN or Mercurial—if you prefer. This book covers only Git, because covering everything would result in a multivolume series, which is difficult to transport.
Next we covered the basic setup of a Rails application, which started with the
rails new command that initializes an application. Then we segued into
setting up the Gemfile to require certain gems for certain environments, such
as RSpec in the test environment. You learned about the beautiful Bundler gem
in the process, and then you ran the installers for these gems so your
application was fully configured to use them. For instance, after running
rails g rspec:install, your application was set up to use RSpec and so
will generate RSpec specs rather than the default Test::Unit tests for your
models and controllers.
Finally, you wrote the first story for your application, which involved
generating a controller and a model as well as an introduction to RESTful
routing and validations. With this feature of your application covered by
RSpec, you can be notified if it’s broken by running bundle exec rspec, a
command that runs all the tests of the application and lets you know if
everything is working or if anything is broken. If something is broken, the
spec will fail, and then it’s up to you to fix it. Without this automated
testing, you would have to do it all manually, and that isn’t any fun.
Now that you’ve got a first feature under your belt, let’s get into writing the next one!